

\( \pi^{*}(\tau\mid q) \propto \widetilde{R}(\tau)^{\beta} \)
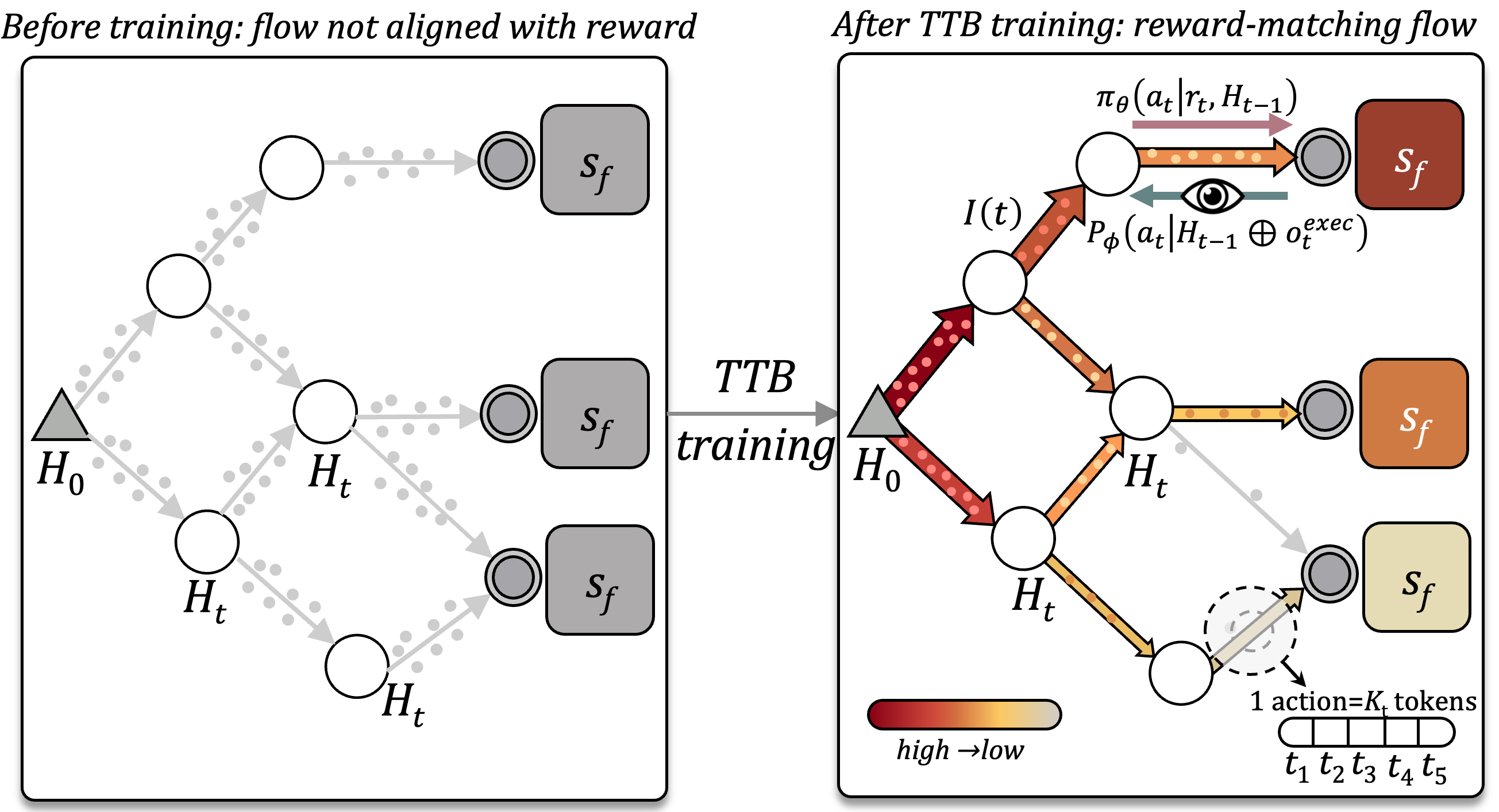
TTB keeps multiple high-reward orchestration paths alive instead of collapsing to one route.
Agentic orchestration with recursive skill evolution
Flow-Driven Recursive Skill Evolution for Agentic Orchestration
A trainable Supervisor learns reward-proportional trajectories, reads hindsight credit from flow, and turns those signals into a self-evolving skill library.
\( \pi^{*}(\tau\mid q)\propto\widetilde R(\tau)^\beta,\quad I(t)=P_F/P_B \)
TTB keeps multiple high-reward orchestration paths alive instead of collapsing to one route.
The residual aligns forward path probability, hindsight backward probability, and terminal reward.
Step importance and skill marginal flow tell the library what to retain, refine, prune, or create.
Evidence path
Each visible block maps to the paper’s action-DAG model, TTB objective, zero-cost credit signal, and phase-boundary skill curation.
Each node is an interaction history \(H_t\); each edge is one orchestration action.
\(a_t\in\{\texttt{skill},\texttt{act},\texttt{accept}\}\)
TTB preserves multiple successful trajectories instead of reinforcing only one mode.
\(\Delta(\tau)/T\rightarrow 0\)
The backward policy reads execution feedback and turns the same loss into per-step credit.
\(I(t)=P_F/P_B\)
Flow diagnostics decide when to evolve and which atomic tips to retain or rewrite.
\(\mathcal S^{(k+1)}=\Phi(\mathcal S^{(k)};\cdots)\)
Overview
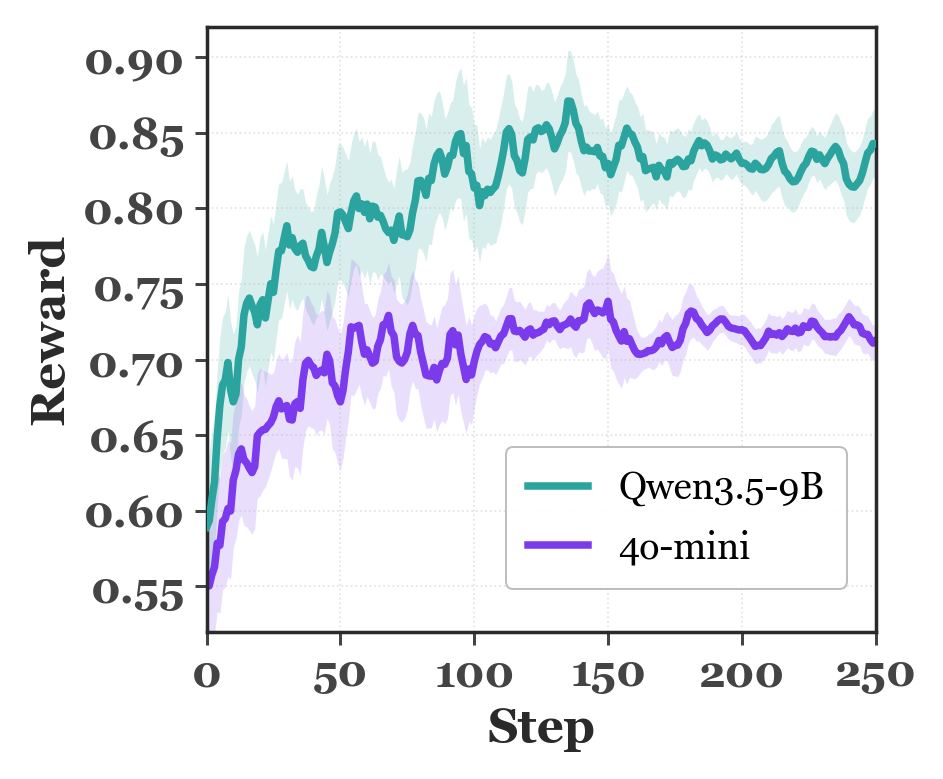
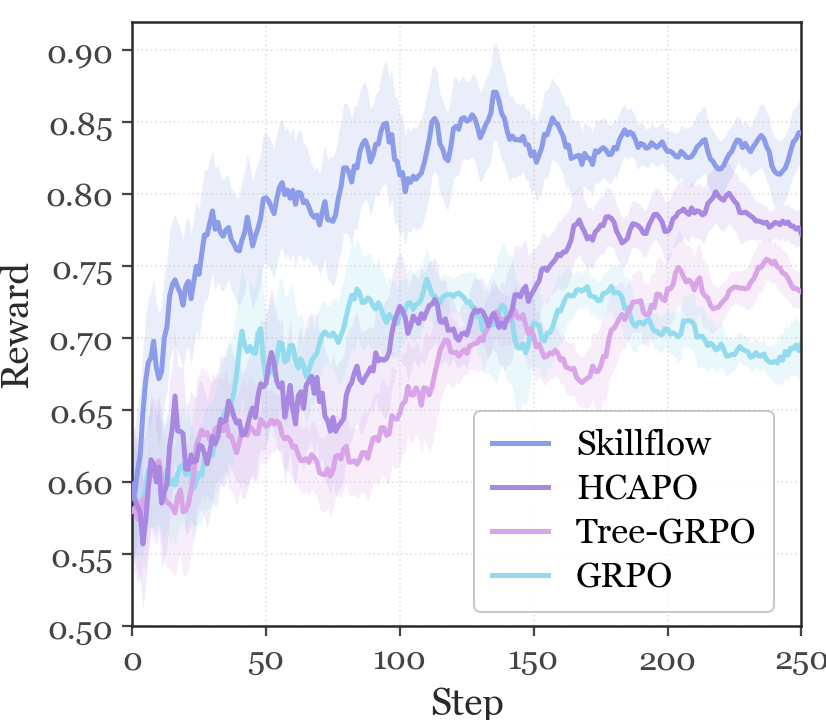
SkillFlow shifts orchestration from static workflow selection to flow-trained decision making, so diverse high-reward trajectories remain visible and actionable.
Direct reward maximization can collapse several valid strategies into one mode, while leaving step-level credit and library updates under-specified.
Tempered Trajectory Balance connects terminal reward, backward credit, and skill marginal flow inside one training-and-evolution loop.
Method
The framework comparison moves from brittle routing, to reward-only learning, to flow-driven orchestration that keeps multiple successful strategies alive.
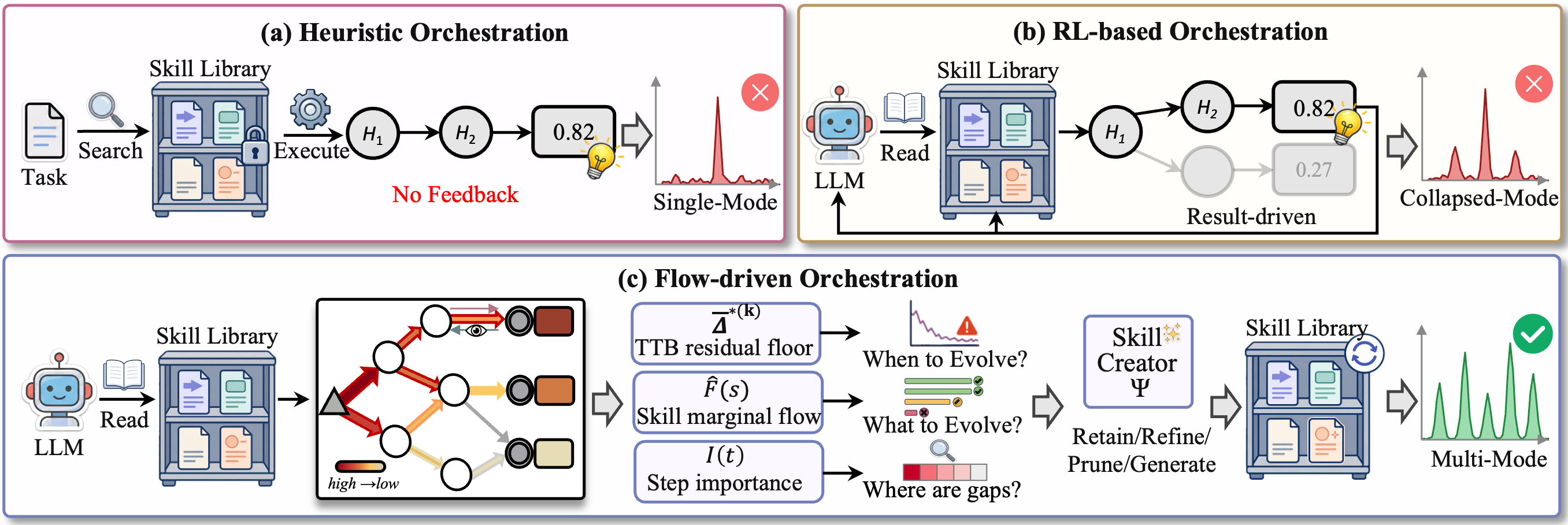
Handcrafted orchestration searches and executes a pre-defined path, so terminal quality does not reshape future skill selection.
Result-driven updates can over-concentrate on one path, losing alternative high-reward trajectories that should remain available.
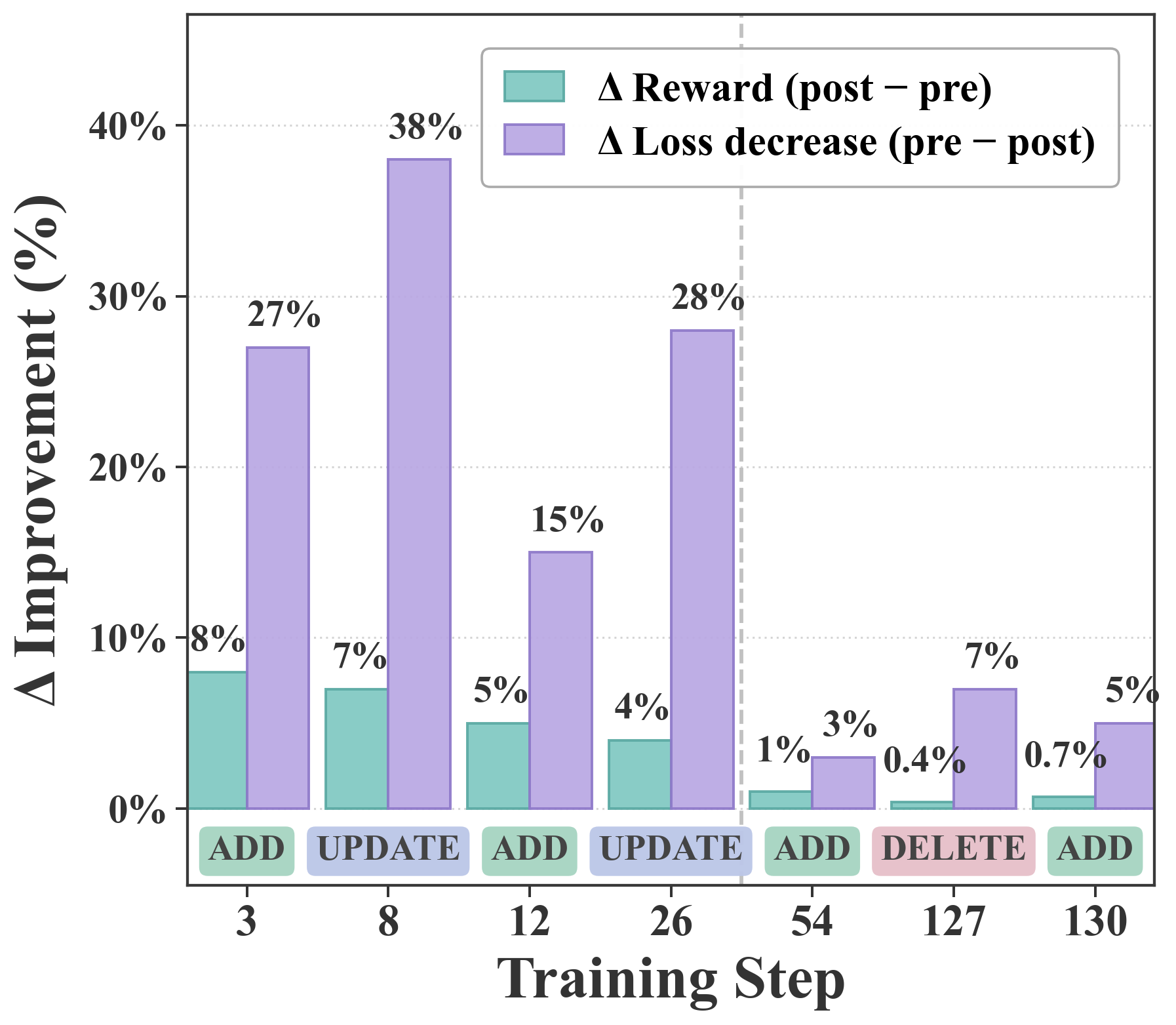
TTB residual flow, skill marginal flow, and step importance turn trajectory evidence into retain, refine, prune, and generate decisions.
The system diagram shows one pass through Supervisor rollouts, TTB training, hindsight credit, and phase-boundary skill-library updates.
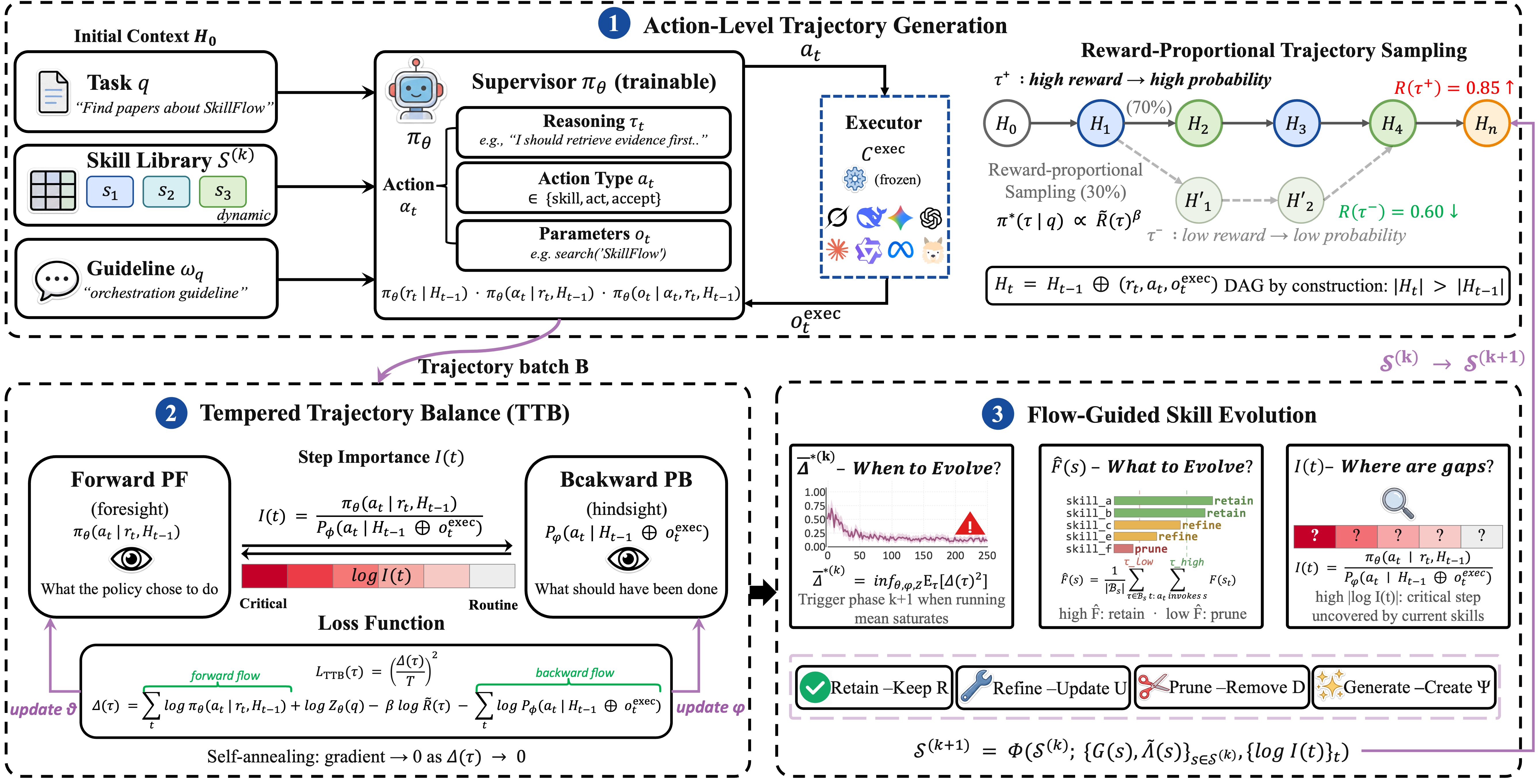
The Supervisor samples skill, act, and accept actions while keeping high-reward paths likely rather than forcing a single route.
The TTB residual aligns forward probability, backward hindsight probability, and terminal reward; their ratio yields step credit.
Skill marginal flow and high-importance gaps decide which skills to retain, refine, prune, or generate for the next phase.
At phase boundaries, SkillFlow reads the TTB residual floor, step importance, skill marginal flow, and CGF stability diagnostics already computed by the loss.
\(\overline{\Delta^2}\) stops falling against the current library’s floor.
\(\log I(t)\) localizes decisions whose value appears only after execution.
\(\hat F(s)\) ranks which skills attract reward-matching probability mass.
\(\Lambda_1^{(s)}-G(s)\) separates reliable tips from context-unstable ones.
\(Z_\theta\) adjusts while the base Supervisor explores.
\(\Phi\) creates candidate atomic tips from success/failure pairs.
\(\hat F(s)\) removes low-flow tips and refines unstable ones.
Flow entropy remains high while the active skill set stabilizes.
Training loop
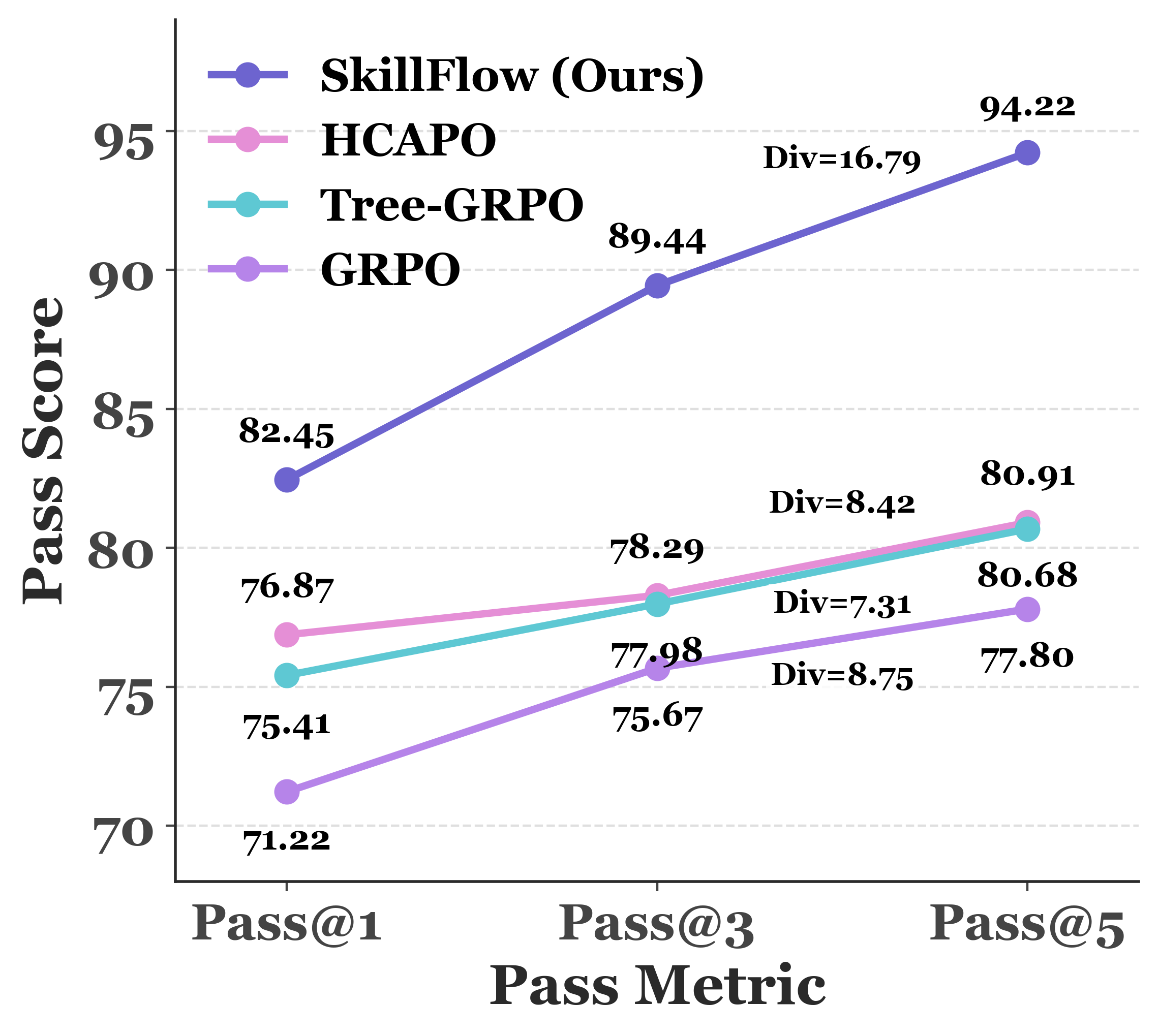
Results
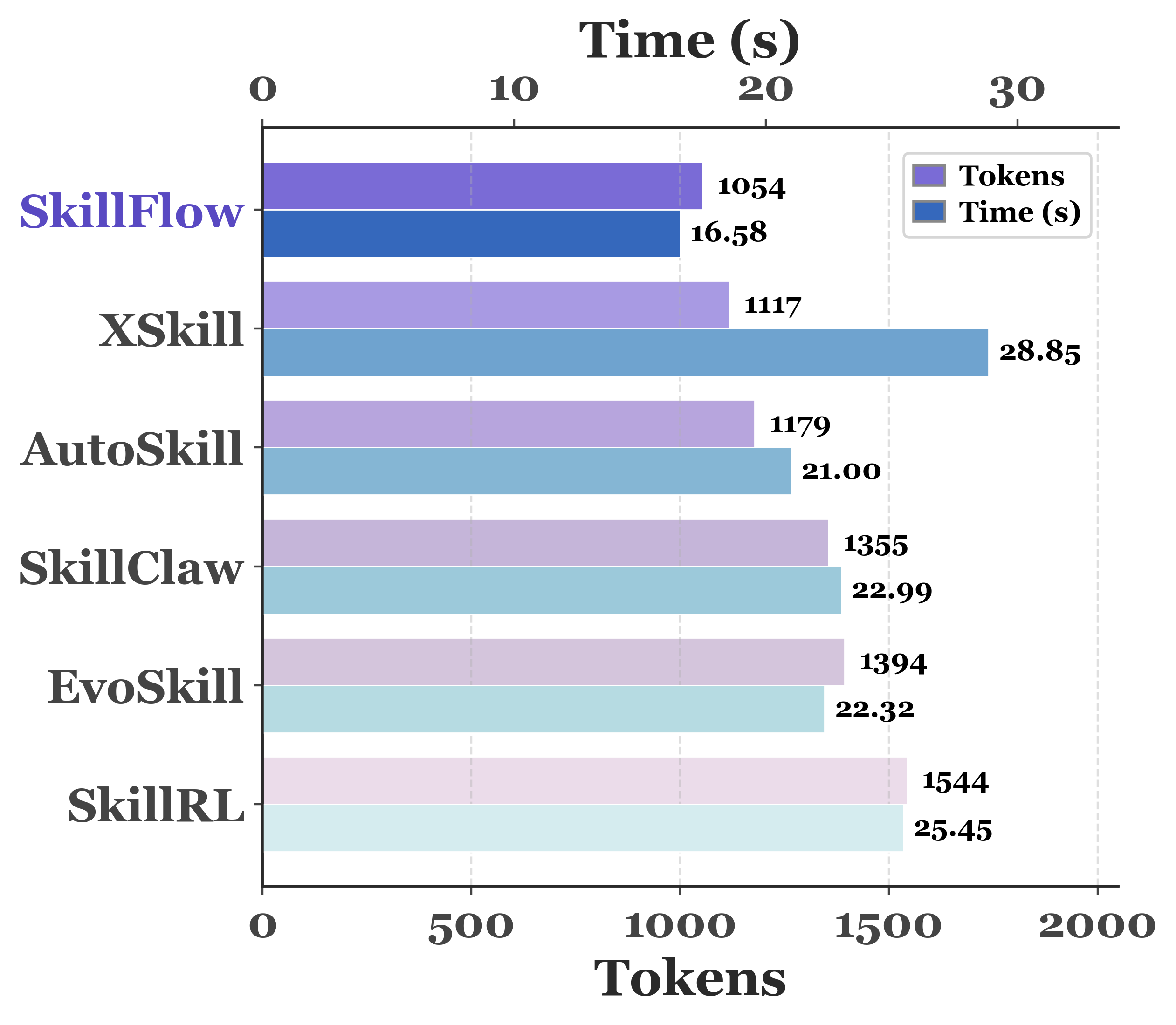
The tabbed metrics mirror the paper’s IID, OOD, and mechanism analysis while keeping the full tables in the PDF.
Figure story

Evaluation scope
HotpotQA, TriviaQA, MuSiQue, and NQ-Open test multi-hop retrieval and answer formation.
AIME 2026, MedQA, MATH-Hard, and GPQA Diamond test mathematical, medical, and scientific reasoning.
SWE-bench and HumanEval measure executable code repair and synthesis behavior.
WebShop, ALFWorld, ScienceWorld, and Mind2Web evaluate long-horizon tool and environment interaction.
Citation
@article{zhang2026skillflow,
title={SkillFlow: Flow-Driven Recursive Skill Evolution for Agentic Orchestration},
author={Zhang, Mingda and Luo, Haoran and Liu, Wenjin and Shen, Tiesunlong and Xiao, Zikai and Cambria, Erik and Tang, Xiaoying},
journal={arXiv preprint arXiv:2605.14089},
year={2026}
}